Formatos abertos como forma de preservação de dados
Será que há alguma relação com o uso de formatos abertos e a preservação de dados em um futuro digital? Isso já é um assunto discutido há muito tempo nos mais diversos âmbitos da tecnologia, sobre formatos de arquivos de imagem, de texto e outros documentos, ou até de pedaços de software que rodam em sistemas fechados, como é o caso das ROMs de jogos de consoles antigos. Sendo, creio eu, a pirataria o movimento contra cultural mais importante nesse âmbito da preservação de softwares proprietários defasados.
Nesses casos, o que sempre salva é o trabalho comunitário. Para preservação de jogos antigos, de sistemas defasados como Game Boy e Mega Drive, a comunidade de emulação faz milagres. Porque sendo franco, pra mim a inovação nas plataformas de Consoles de jogos morreu há muito tempo, hoje em dia os sistemas se aproximam cada vez mais de computadores otimizados para jogos, algo como o que a Valve vem tentando fazer com o Steamdeck. O Xbox é um Windows tunado. Playstation e Switch são praticamente Unix.
Mas sem divagações, o que quero trazer é a necessidade de conscientização sobre não só o conteúdo do pedaço de software, mas da sua forma também. Sobre como está disposta essa informação dentro do arquivo, e onde está localizado no espaço tempo.
Quando utilizamos um computador pessoal, as coisas para nós parecem estar bem localizadas nesse sentido. Sabemos que aquele arquivo está no endereço C:\Users\eu\Documentos\arquivo.txt, ou /home/eu/Documentos/arquivo.txt no Unix, e que toda essa estrutura está no nosso HD/SSD que está no nosso computador físico.
Quando jogamos em um Google Drive da vida, começamos a perder um pouco o lastro com a materialidade desse dado, elas passam a estar “na Nuvem”, em algum dos servidores da Alphabet. É uma relação de confiança muito frágil.
Mas novamente, isso já é outra problemática que não pretendo me aprofundar aqui 🤓, a questão da segurança dos dados e do colonialismo digital são assuntos discutidos por diversos intelectuais da atualidade, como o brasileiro Sérgio Amadeu da Silveira, ou o bielorrusso Evgeny Morozov. Isso de marxistas à liberais e libertários, ainda muito se discute maneiras seguras de garantir a segurança dos dados fora de redes centralizadas e que ao mesmo tempo que ações digitais não fiquem invisíveis para crimes virtuais.
O que quero falar aqui vai mais no sentido de ações individuais, de primeiro trazer essa consciência para o usuário de que é ele que produz materialmente esse dado, e esse dado ocupa um espaço físico na realidade, não é esoterismo. E segundo, de contribuir com a noção de que a forma como está disposto o conteúdo do arquivo importa, principalmente quando falamos da sua preservação.
Sobre formatos de arquivo
Formatos como .docx, .doc, são os formatos chamados proprietários, tecnologias da Microsoft e amplamente suportados por seus produtos. Legalmente você só pode editar arquivos DOCX dentro do Microsoft Office, apesar de hoje haver diversas ferramentas de conversão ou aplicativos que implementam suporte a edição desses formatos. Mesma coisa para o .psd e .ai da Adobe, para Photoshop e Illustrator, apesar desses dois formatos terem ainda menos suporte fora de suas respectivas plataformas.
O ruim dessa abordagem é que pelo fato desses formatos ficarem amarrados à essas plataformas, eles também evoluem junto com elas, no sentido de que pode ser muito fácil a perda de compatibilidade de versões antigas com mais novas (dependendo do quão distante são as versões). Softwares proprietários tem muito mais chances de ter seu descobrimento prejudicado com o crescimento dos dados da internet, pois algumas empresas simplesmente param de distribuir versões mais defasadas de seus softwares. Hoje em dia, como falei, a única resistência nesse sentido é a pirataria. Com tecnologias livres isso também poder acontecer mas é bem mais mitigado, formatos abertos são livres para serem implementados em diversos programas, e também é muito mais fácil de encontrar versões defasadas dos softwares.
Para arquivos de texto isso é ainda menos trivial, afinal no fundo é somente texto, não há necessidade de toda uma formatação binária e complicada em relação à isso. Porém se ainda assim há essa necessidade e a de utilizar uma suíte office, recomendo trabalhar como o ODT (OpenDocument Text), que não está amarrado por licença e deve ser suportado em praticamente todos os editores de documentos.
Porém para textos simples, recomendo fortemente o uso de Markdown. Já tem alguns anos que venho utilizando para escrever minhas notas e é extremamente prático. Desde o ano passado também venho adotando LaTeX para escrever meus trabalhos da faculdade. Ambos fazem parte das chamadas linguagens de marcação, junto com o HTML, XML e outros formatos. São basicamente arquivos de texto tunados, sendo possível manipulá-los em qualquer editor simples. Servem basicamente para guardar informações de texto porém de maneira que possamos facilmente adicionar marcações como negrito, itálico, link,
adicionar títulos,
de diferentes tamanhos,
e por aí vai. Onde no arquivo Markdown de fato, você teria algo assim:
... facilmente adicionar marcações como **negrito**, *itálico*, [link](https://blog.canoi.dev.br),
### adicionar títulos,
#### de diferentes tamanhos,
...
E aí cabe ao programa que for ler o arquivo montá-lo de maneira visual para o usuário. O arquivo de texto não é feito para ser lido diretamente (apesar de ser possível), somente para edição, e hoje em dia nem isso é necessário, pois já temos ótimos editores para Markdown, onlines ou não, o próprio Google Docs hoje suporta (porém só há suporte na marcação do editor, para salvar ele usa formato próprio), o GitHub a mesma coisa, o Obsidian que é um ótimo editor offline. E a maioria desses formatos é facilmente conversível entre si Markdown <-> LaTeX <-> HTML, e obviamente, todos exportáveis para PDF, principal formato de distribuição de documentos finalizados, somente para leitura. Inclusive o mais comum é utilizar essa conversão Markdown <-> HTML para gerar arquivos para blogs ou páginas de sites.
O melhor de usar formatos abertos é exatamente que sua forma é legível na maioria das vezes, mas mesmo que não seja e seja um arquivo binário, toda a especificação para cada uma das versões é bem descrita e continuará disponível enquanto o projeto existir. Se uma comunidade o abraçar, sua morte é ainda menos provável.
Diferente de grandes corporações que vez outra dão luz à um projeto para o matar pouco tempo depois (cof, Google Stadia, cof cof). Geralmente não há liberação de código fonte nem nada nesse sentido; bem que poderia haver já que a ideia é tornar o projeto deprecado, não é? Mas no capitalismo é bem difícil iniciativas assim, apesar de existir, e geralmente dar certo como no caso do Blender, que surge como projeto privado, e tem seu código aberto em 2002 após a empresa responsável fechar suas portas e o seu fundador, Ton Roosendaal, decidir a lançar como um projeto aberto em uma organização sem fins lucrativos. A comunidade abraçou o projeto e hoje ele é um dos principais softwares de modelagem 3D do mercado, é amplamente utilizado em jogos e animações.
É exatamente nesse sentido que eu advogo em mantermos documentos em formatos abertos, apesar de existirem exceções, não dá para esperar boa vontade de nenhuma Big Tech em abrir alguma de suas tecnologias. Adotar formatos simples e abertos te garante a facilidade de editar arquivos em qualquer editor de texto vagabundo, havendo a opção de usar editores mais completos, como o Obsidian que tem diversos plugins, corretor ortográfico, e formas de visualizar as relações entre seus dados em um grafo relacional. Com isso eu tenho a garantia que o conteúdo do meu arquivo estará sempre ao meu alcance.
Sobre formatos de texto
Quando se trata do digital, lidamos com uma estrutura meio difusa. Temos o arquivo, esse arquivo vai estar armazenado em uma estrutura de bits na memória persistente do nosso computador (HDs ou SSDs). Porém muito pouco nos interessa o hardware, ou como esse arquivo está disposto, no fim o que nos interessa como usuário é que isso seja disposto de forma legível para nós na tela do nosso computador.
O importante é que a ordenação dos símbolos faça com que as palavras façam sentido. Então é necessário convencionar esses valores armazenados na nossa máquina com caracteres que os programas irão mostrar para nós. Isso é totalmente abstraído para nós através do sistema operacional e dos softwares editores de texto, porém ainda acho importante entender o básico de convencionamento de formatos para entender com o que estamos lidando.
Os computadores não seriam interoperáveis da maneira que são se não fossem compostos de diversos padrões, como a forma como um arquivo de texto deve ser representado, por exemplo. A principal convenção hoje é a Tabela ASCII (American Standard Code for Information Interchange), criada em 1960. Ela possui valores de 0 a 127, onde cada um representa um caractere diferente:
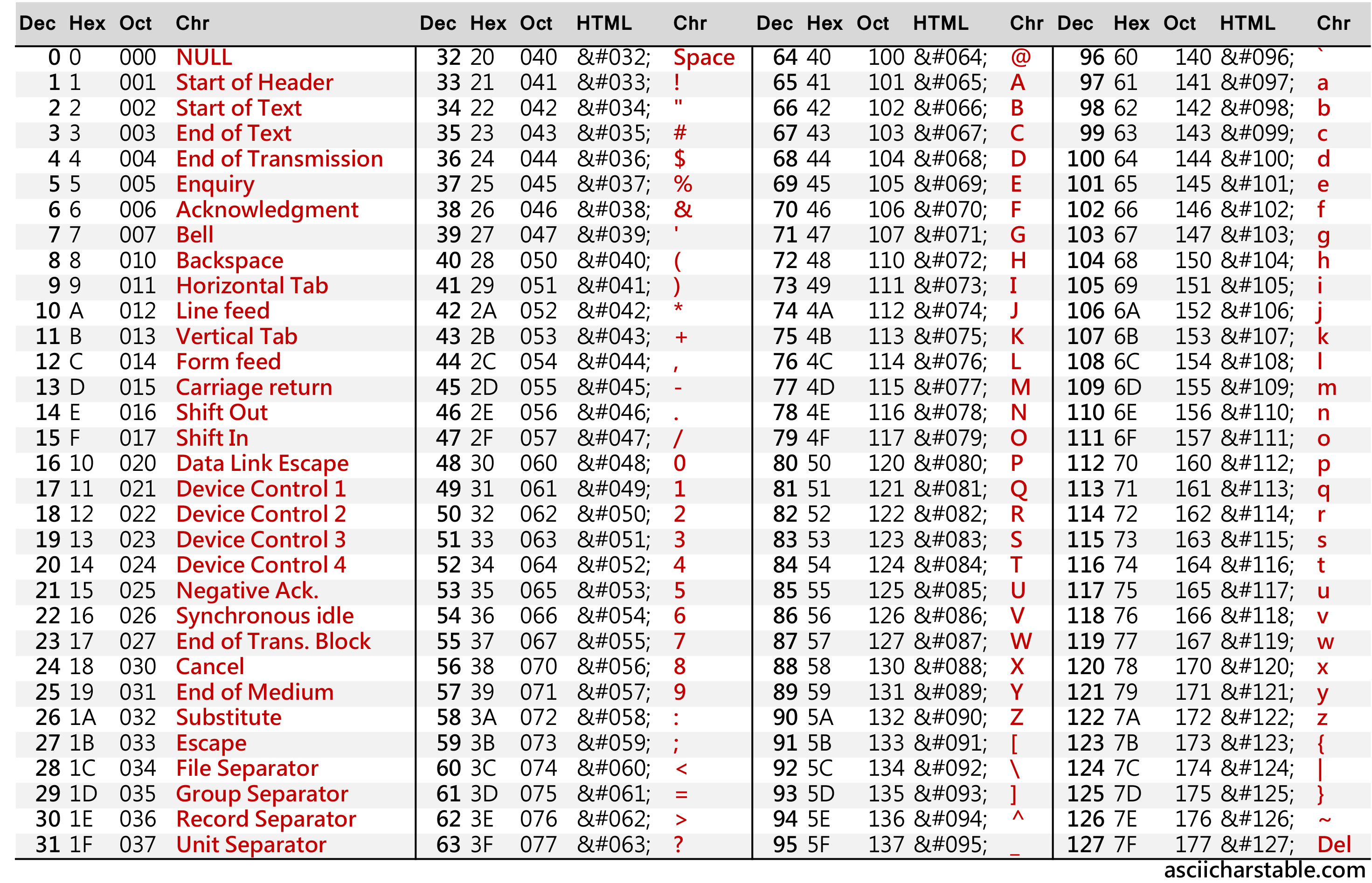
Perceba que ela não permite caracteres especiais como õ, à, í ou ç, e outros caracteres latinos. Perceba também que há a necessidade de representar outros alfabetos como asiáticos e árabes, então outra convenção surge, a Unicode com formatos como UTF-8 e UTF-16. Os formatos UTF são o que chamamos de formatos codificados e requerem conversão para serem utilizados, pois a quantidade de bytes usadas por um caractere pode variar de 1 a 4 bytes. Para isso, o primeiro byte serve como mantenedor dessa informação, de quantos bytes serão necessários para ler esse caractere. Apesar de simples, isso complexifica um pouco a interpretação do arquivo, então para ler nesse formato, o editor precisa também saber como fazer sua decodificação. Abrir um arquivo de texto em UTF-8 em um editor que só suporta ASCII não vai dar muito certo. Porém o UTF-8 é compatível com ASCII, então um editor que lê por padrão em UTF-8 não deve ter problemas em ler um texto ASCII.
Então não é somente no formato do arquivo que precisamos nos atentar, mas o formato de seu texto também. A convenção padrão para caracteres estendidos do ASCII, ou seja, para caracteres latinos, árabes, russos, asiáticos, …, é o UTF-8, o UTF-16 também é utilizado mas tem bem menos compatibilidade com o ASCII, pois no seu caso cada caractere pode variar de 2 a 4 bytes. Também existe o UTF-32, mas enfim, usem UTF-8.
Inclusive, caso seja programador e queira um projeto interessante, você pode tentar implementar um decodificador de UTF-8 se baseando na sua especificação, é algo bem simples e interessante para aprender mais sobre manipulação bit a bit. Ou até mesmo brincar de criar sua própria tabela de caracteres, codificação e editor.
Conclusão
No mais é isso, vi um vídeo interessante no canal do Vinícius Spira, onde ele fala brevemente sobre essa questão do uso do Markdown para preservação do dados digitalmente, exatamente por ser um formato bem simples de marcação, é possível abri-lo em qualquer editor de texto. Fiquei bastante pensativo sobre essa questão da preservação de dados digitais, já que os sistemas digitais tem diversos convencionamentos, e a tendencia de alguns é simplesmente desaparecer com o tempo, então acho interessante uma reflexão nesse sentido.